What is an AI search content engine?
An AI search content engine is an operating workflow that converts site facts, research, and editorial rules into citation-ready pages for answer engines and classic search. It is not a drafting tool. It is the pipeline that defines the site profile, gathers entity facts, structures answers for retrieval, publishes through CMS or headless delivery, and refreshes the archive on a schedule.
For B2B SaaS, this matters because AI systems no longer rank links — they synthesize answers from retrieved sources and cite a small set of pages. A content engine exists to make sure your pricing, integrations, comparisons, and category definitions are the extractable, trusted, source-backed material those systems pull from. Drafting is one step inside it. The rest is profile setup, factual grounding, structured publishing, schema, internal linking, and measurement loops.
The category sits next to — but is distinct from — AI writing tools, AI visibility analytics, enterprise search, and answer-engine site search. Those tools either draft text, monitor mentions, or retrieve from your own corpus. A content engine produces the public, citable source material that ChatGPT, Perplexity, Google AI Overviews, Gemini, Claude, and Copilot pull into their generated answers.
What are AI search engines and how do they work?
AI search engines combine retrieval with generation: they fetch documents from one or more indices, then use a large language model to synthesize a cited answer instead of returning a ranked link list. According to You.com, this pipeline runs in five stages — content gathering, indexing, vectorization, retrieval, and synthesis through retrieval-augmented generation (RAG).
In operator terms, a single user query triggers query fan-out (multiple sub-queries run in parallel), parallel retrieval across web and proprietary indices, filtering and consolidation of the candidate passages, and then LLM synthesis with source attribution. An AI search engine is a retrieval-and-generation system, not a ranking system. ChatGPT Search, Perplexity AI, Google AI Overviews, Gemini, Claude, Bing Copilot, You.com, Phind, Kagi, and Grok on X all follow variations of this pattern, but they differ on which crawlers they use, which indices they retrieve from, and how aggressively they cite.
The practical consequence: your page has to survive retrieval (be indexed and chunkable), survive synthesis (have a clean, extractable answer), and earn the citation slot (be source-credible).
What is an AI answer engine, and how is it different from a content engine?
An AI answer engine takes a natural-language question, searches a defined body of content, and returns a cited answer grounded in that corpus — the definition AskDewey uses for the category. A content engine, by contrast, produces the public source material those systems retrieve from. They sit on opposite sides of the retrieval boundary.
Six adjacent categories get conflated in the market. Here is how they actually differ:
| Category | Job | Examples | Output |
|---|---|---|---|
| AI search engine | Retrieve from the open web, generate cited answer | ChatGPT Search, Perplexity, Google AI Overviews | Synthesized answer with citations |
| AI answer engine | Retrieve from a defined corpus, return cited answer | AskDewey, custom RAG over docs | Grounded answer from your content |
| AI search content engine | Publish citable source pages for AI systems | Mentionwell | Articles, comparisons, glossary pages |
| AI writing tool | Draft text on demand | Generic LLM editors | Draft copy |
| AI visibility analytics | Monitor citations and mentions | Brand monitoring tools | Dashboards and prompt reports |
| Enterprise / site search | Index and retrieve owned content | Azure AI Search, Algolia, Elasticsearch, Google Workspace search | Search results from your corpus |
Microsoft's documentation describes Azure AI Search as a managed service that connects enterprise content to LLMs for grounded answers, distinguishing classic search from agentic retrieval that runs parallel, iterative, LLM-assisted queries. Tools like Azure AI Search, Azure OpenAI, Microsoft Foundry, Algolia, and Elasticsearch retrieve and answer from content you already own. A content engine's job is upstream: it publishes the pages those retrieval systems — and the open-web answer engines — choose to cite.
Why do B2B SaaS teams need one workflow for ChatGPT, Perplexity, Google AI Overviews, Gemini, Claude, and Copilot?
Buyers don't move through one engine — they move across them, often inside the same week. Running separate SEO, AEO, GEO, and LLMO efforts produces operational drag, contradictory page structures, and inconsistent entity facts across surfaces that all need the same things: crawlable pages, direct answers, consistent entity names, and source-backed comparisons.
Each engine has its own retrieval quirks. ChatGPT and Copilot lean on Bing's index. Google AI Overviews and Gemini draw from Google's. Perplexity runs its own crawler. Claude pulls from web search and connectors. But the underlying content requirements converge: an extractable answer in the first one to two sentences, consistent product naming across the web, citable facts (pricing, integrations, security posture), and clean technical access for GPTBot, ClaudeBot, and PerplexityBot.
A single workflow avoids three failure modes: pages optimized for Google snippets that don't chunk cleanly for RAG, pages built for AI extraction that lose classic search rankings, and inconsistent entity facts that cause one engine to cite a competitor while another cites you. For platform-specific mechanics, the ChatGPT, Perplexity, Google AI Overviews, Gemini, Claude, and Copilot guides cover the per-engine details — but the underlying publishing system should be one.
How do B2B SaaS companies get recommended by AI search engines?
AI assistants answering software queries return a direct answer plus a short list of options with citations — typically 3–5 options, according to Xseek's B2B SaaS AEO playbook. To make that shortlist, your content has to publish the facts those models check before recommending: pricing, integrations, feature comparisons, API details, security posture, common use cases, named alternatives, and third-party validation.
B2B buyers also ask longer, constraint-heavy questions than consumer searchers — Xseek cites the example of "CRM with Salesforce integration under $50/seat." Those queries reward pages that explicitly publish integration lists, price tiers, and seat math, not pages that bury them behind a "Contact sales" CTA. According to Xseek, content with cited sources saw a 40% visibility boost in generative engines, attributed to a 2024 Princeton KDD study.
Buying committees compound the requirement. Gartner data cited by Xseek shows a B2B purchase involves 6–10 decision-makers on average, and CTOs, CFOs, end users, and marketing leaders ask different questions:
- CTOs ask about API rate limits, SSO, deployment models, and SOC 2 status.
- CFOs ask about per-seat pricing, contract terms, and total cost over 12–24 months.
- End users ask about onboarding time, daily workflow fit, and integrations they already use.
- Marketing and ops leaders ask about reporting, CRM integration, and migration support.
A content engine should produce a role-specific page or section for each of these question shapes, not one generic "features" page. The teams that get cited are the ones that publish the constraint, the integration, and the price as extractable facts — not as marketing prose.
Get your site structured for AI citations across ChatGPT, Perplexity, AI Overviews, Gemini, Claude, and Copilot — Get My Site GEO Optimized.
How do AEO, GEO, LLMO, and SEO work together in the content pipeline?
Each acronym names a different job inside the same publishing system, not a separate strategy.
| Workflow | Job | Primary surface |
|---|---|---|
| SEO | Crawlability, rankings, demand capture | Google, Bing classic results |
| AEO | Make answers quotable and extractable | Featured snippets, AI Overviews, ChatGPT cited blocks |
| GEO | Help generative engines synthesize and cite | ChatGPT, Perplexity, Gemini, Claude answers |
| LLMO | Strengthen entity recognition and brand facts in LLMs | Recommendations, mentions, comparisons in LLM outputs |
SEO keeps the page indexable and the URL ranking. AEO shapes the answer block — the 40–60 word extractable passage that an answer engine can lift verbatim. GEO ensures the broader page (comparisons, sourced claims, structured data) is synthesizable into a generated answer with your URL cited. LLMO works at the entity layer: consistent brand naming, factual associations, and third-party signals that make a model "know" who you are without retrieval.
Inside one pipeline, these collapse into a single editorial spec: exact-query H2, answer-first opening, source-backed claims, comparison table, schema, internal links, refresh schedule. AEO, GEO, LLMO, and SEO are not competing strategies — they are sequential filters every page should pass before it ships. The differences between them are explored in AEO vs GEO vs LLMO: Which Workflow Fits Your Team? and the glossary entries for AEO, GEO, LLMO, AI SEO, AISO, and AIO.
What content formats are most likely to be extracted and cited by AI answer engines?
Answer engines extract from pages that look like reference material, not narrative essays. The patterns that survive retrieval and synthesis are consistent across the major sources:
- Exact-query H2 headings. When the heading restates the user's question, retrieval matching improves. Xseek recommends this as a core AEO requirement.
- Answer-first openings. According to Semai, the most important answer should appear in the first one to two sentences of each section. Averi recommends a 40–60 word extractable answer block at the top of each section.
- Self-contained chunks. Otterly describes self-contained content units of roughly 80 words that answer a single question without needing context from elsewhere on the page.
- Factual density. Otterly recommends one specific data point per 150–200 words to give synthesis layers something to lift.
- Clean comparison tables. AuraSearch notes that AI models are more likely to cite clean HTML tables for product comparisons than the same information buried in paragraphs.
- Source-backed claims. Inline attribution to named sources signals trust to both crawlers and synthesis layers.
- Short paragraphs and bullet lists. Both improve chunk-level retrieval, where the engine grabs a passage rather than the whole page.
Schema markup supports — but does not replace — the above. Use FAQPage schema only when the page contains genuinely distinct questions a user would search; HowTo schema for sequential processes; Article schema as the baseline. Avoid generic FAQ stuffing — it inflates page length without producing extractable answers.
How do you optimize content for AI search from brief to publish?
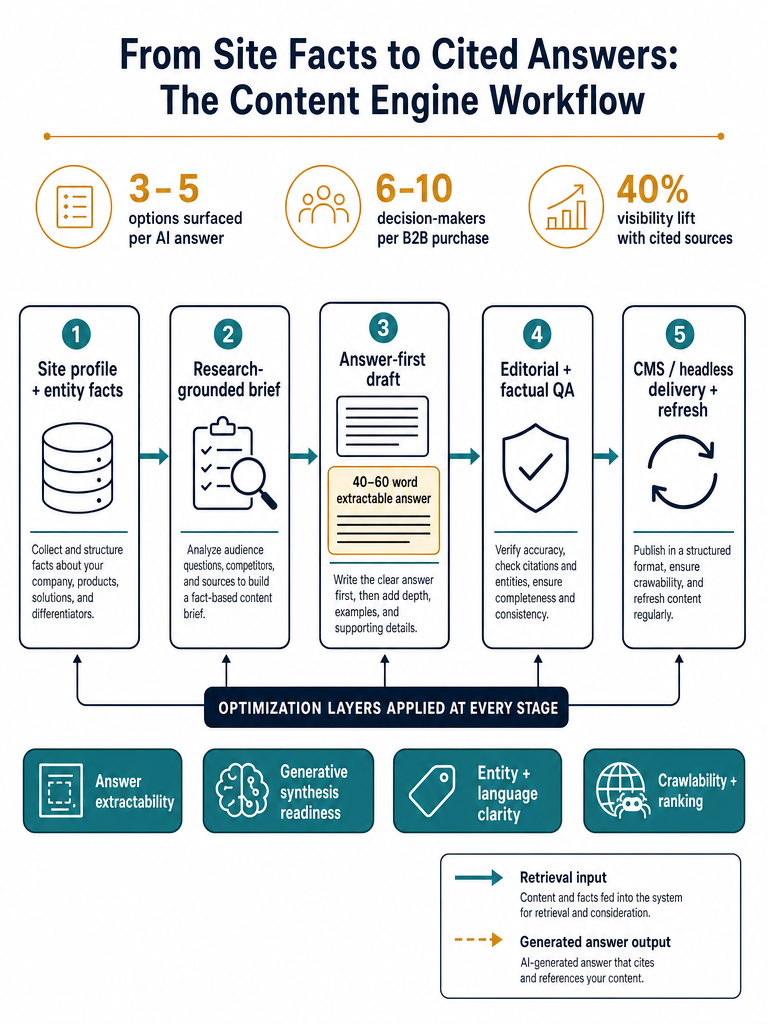
Citation-ready pages come out of an eleven-stage pipeline that runs from domain onboarding through scheduled archive refreshes — each stage produces a specific artifact (site profile, entity fact set, brief, draft, schema, published URL, refresh log) that the next stage depends on. Skipping stages is the most common reason teams produce content that ranks but doesn't get cited.
The stages, in order:
- Onboard the domain. Connect the CMS or headless endpoint and confirm crawler access for GPTBot, ClaudeBot, and PerplexityBot.
- Build the site profile. Capture brand voice, audience, pain points, pitch rules, competitor exclusions, and CTA logic so every brief inherits them.
- Collect entity facts. Pricing, integrations, API documentation, security posture, named alternatives, use cases, and third-party validation — published as canonical, citable assets.
- Map AI-search questions. Pull the actual prompts buyers ask across ChatGPT, Perplexity, AI Overviews, Gemini, Claude, and Copilot for your category.
- Cluster topics. Group questions into pillar pages, cluster pages, glossary entries, and comparison pages. Tag each by intent and target engine.
- Create research-grounded briefs. Every brief should carry the answer, the sources, the entities, the must-answer questions, and the schema spec.
- Draft answer-first sections. Open with the 40–60 word answer block. Add tables, sourced claims, and role-specific subsections.
- Run factual and editorial QA. Verify every statistic against its source. Check entity consistency. Strip filler.
- Publish through CMS or headless delivery. Preserve URLs, apply schema, set canonical tags, update internal links.
- Schedule refreshes. Pricing pages, integration lists, and statistics get the shortest cycles; evergreen definitions get longer ones.
- Measure citation outcomes. Track which pages are getting cited by which engines, and feed gaps back into the brief queue.
This is where Mentionwell sits. It operationalizes the pipeline as a content engine — site profile, research-grounded briefs, answer-first drafting, schema and internal linking, CMS or headless publishing, and scheduled archive refreshes — so the same workflow runs across one site or hundreds without losing brand consistency. It is not a drafting tool that produces a Word doc; it is the publishing system that ships the pages AI engines retrieve from.
Can schema markup help AI search visibility?
Schema markup helps machines understand page type and structure, but it does not replace useful, citable content. The page still has to answer the question better than the alternatives — schema only tells retrievers what kind of answer they're looking at. AuraSearch frames schema and crawlability as technical access requirements that sit underneath content quality, not above it; Otterly lists AI crawler access, clean HTML, and schema markup as three of ten foundational signals, alongside answer-first formatting and source attribution.
The technical baseline that supports retrieval and citation:
- Clean, semantic HTML so passages chunk predictably for RAG.
- Crawlability and indexability for GPTBot, ClaudeBot, PerplexityBot, and the major search bots — confirmed in robots.txt rather than assumed.
- Schema types matched to content: Article for editorial pages, HowTo for sequential processes, FAQPage only when distinct questions exist on the page.
- Internal links that signal topical clusters and pass authority between pillar and cluster pages.
- Canonical URLs so duplicate paths don't split signals across the site.
llms.txtas an emerging convention for declaring AI-relevant content. It is not yet a universal standard, but adoption is rising — see What Is LLMs.txt in 2026? for placement and structure guidance.
If crawlers can't reach the page, no amount of answer-block engineering will produce a citation. Treat schema and crawl access as table stakes, not differentiators.
How should teams scale topic clusters and programmatic SEO without thin pages?
Programmatic SEO works in AI search only when editorial controls survive the volume. The failure mode is well documented: thousands of templated pages with shuffled variables, no entity validation, and no source attribution. AI engines deprioritize this material because it doesn't chunk into trustworthy answer blocks.
A content engine should impose six controls on programmatic and cluster output:
- Template variation. Each generated page needs distinct opening, distinct comparison framing, and distinct examples — not just swapped keywords.
- Duplicate-risk checks. Run similarity scoring across the cluster before publishing; collapse near-duplicates into one stronger page.
- Entity validation. Confirm every named product, integration, or vendor against a canonical entity list before the page ships.
- Source attribution. Every factual claim needs a named source — programmatic doesn't excuse "studies show."
- Human QA gates. Sample-review programmatic batches; reject any page where the answer block isn't self-contained.
- Internal linking architecture. Pillar pages, cluster pages, and glossary entries should interlink by entity and topic, not by random anchor text.
For agencies and multi-site operators, the additional layer is governance: brand-consistent voice, competitor exclusion lists, and CTA logic enforced as templates across every domain — not re-litigated per article. The teams that scale programmatic content without losing citations are the ones that publish fewer, denser pages with stricter editorial rules, not more pages with looser ones.
How should teams measure and refresh AI search content after publishing?
Rankings alone don't tell you whether AI engines are citing you. The operational KPIs for an AI search content engine are different:
- Citation frequency — how often a page is cited by ChatGPT, Perplexity, AI Overviews, Gemini, Claude, and Copilot for tracked prompts.
- Answer inclusion — whether the page's answer block is being quoted verbatim or paraphrased.
- Cited-page freshness — the age of pages currently earning citations, used to prioritize refreshes.
- Prompt-set coverage — the share of buyer prompts in your category where you appear in any cited slot.
- Engine coverage — distribution across the major answer engines, not concentration in one.
- Organic performance — classic SEO metrics, kept as a parallel signal.
- Human QA notes — qualitative review of which answers are accurate, which are stale, and which are wrong.
Refresh triggers should be operational, not calendar-based. Update when pricing changes, integrations ship or sunset, statistics age past 18 months, an answer engine starts citing a competitor on a tracked prompt, the answer block underperforms in QA, or new platform behavior (a Gemini update, a new Perplexity model) shifts retrieval patterns.
How should you choose an AI search content engine for SaaS or agency operations?
The buying decision is choosing a repeatable citation-shaped publishing system, not buying another drafting tool or visibility dashboard. Use this checklist when evaluating vendors:
| Requirement | What to verify |
|---|---|
| Site profile setup | Brand voice, audience, pain points, competitor exclusions, CTA logic stored as inputs every brief inherits |
| AEO + GEO + LLMO + SEO support | All four workflows applied per page, not as separate products |
| Research grounding | Every factual claim attributed to a named source in the draft |
| CMS and headless publishing | Native integration with WordPress, headless CMSs, or API delivery — not copy-paste workflows |
| Schema and crawlability | Article, HowTo, FAQPage applied appropriately; crawler access verified |
| Programmatic SEO controls | Template variation, duplicate checks, entity validation, human QA gates |
| Multi-site governance | Brand-consistent rules enforceable across many domains |
| Refresh workflows | Scheduled archive refreshes with URL preservation and citation updates |
| Measurement loops | Citation frequency and prompt-set coverage, not just rankings |
Ask the vendor to show you a published page produced by their pipeline. Read the first 60 words of each section. Check whether statistics are attributed. Look at the comparison tables. If the page reads like generic SEO filler, the engine behind it is a drafting tool with marketing on top.
The right AI search content engine produces pages you'd be willing to defend to a CFO and willing to have ChatGPT cite verbatim — same standard, both audiences. That is the bar.
Mentionwell is built for that bar: a content engine that runs the full pipeline — site profile, research, answer-first drafting, schema, CMS or headless publishing, programmatic controls, and archive refreshes — so AEO, GEO, LLMO, and SEO operate as one workflow across one site or hundreds. If your team is publishing into AI answer surfaces and classic search at the same time, Get My Site GEO Optimized and we'll show you what citation-ready output looks like on your domain.
Sources
- 3 Ways B2B SaaS Startups Can Optimize for AI Search Todayariadpartners.com
- AI Search Visibility Stats That Might Surprise B2B SaaS Marketerswww.columnfivemedia.com
- How to Rank Your B2B SaaS Website on AI Searchgrowthproai.com