What Is an AEO Content Strategy for an Existing SEO Archive?
An AEO content strategy is the practice of restructuring published pages so ChatGPT, Perplexity, Google AI Overviews, Gemini, Claude, Microsoft Copilot, featured snippets, and voice search can extract, cite, and reuse them as direct answers. For teams with an existing SEO archive, it is almost always faster than starting from scratch — those URLs already carry authority, internal links, and topical depth; what they usually lack is answer-first structure.
The shift is structural, not philosophical. Traditional SEO pages were written with long human introductions, narrative buildups, and keyword-led H2s. Answer engines reward the opposite: a question-shaped heading, a 40–60 word direct answer, and self-contained sections that make sense out of context. Most brands already have blog posts, whitepapers, product guides, and research reports that can be reshaped this way (Source: Relevant Audience), which is why archive conversion — not greenfield publishing — is the highest-leverage starting point.
An AEO content strategy treats your archive as a citation surface: each page is a candidate answer, each section is a candidate quote, and each entity is a topical signal that AI systems use to decide whether your domain owns the question.
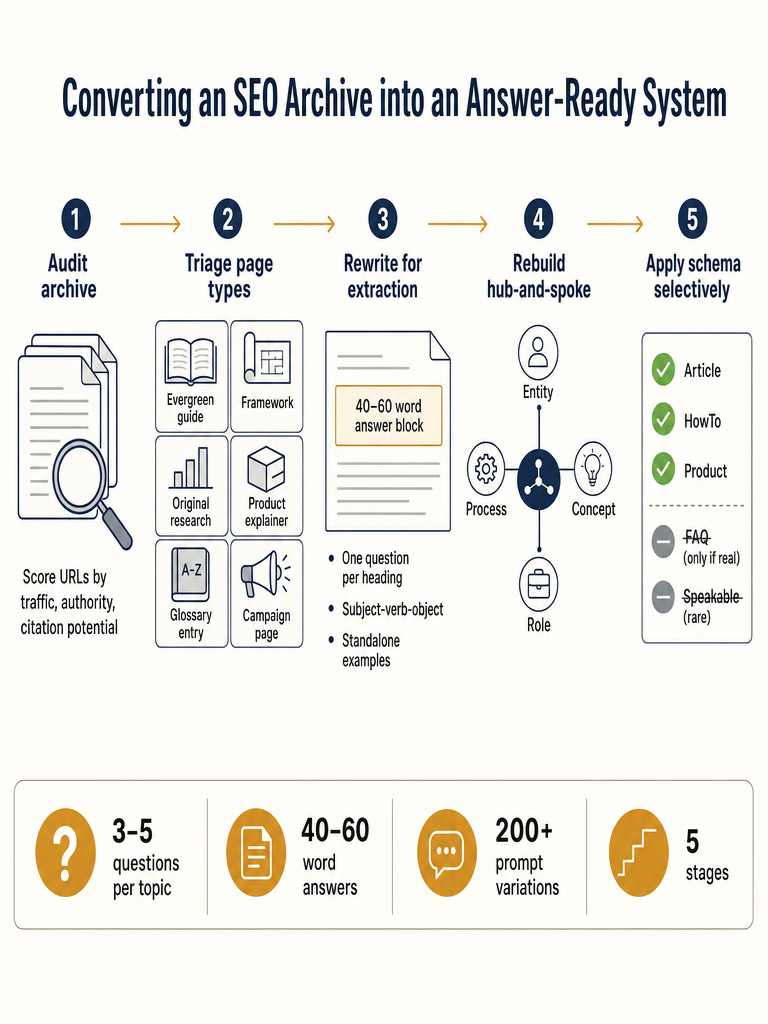
This guide walks through that conversion as an operating system: triage which URLs to refresh first, rewrite sections for extraction, rebuild hub-and-spoke links, apply schema selectively, prevent cannibalization, and measure citations across answer engines.
AEO vs SEO, GEO, and LLMO: What Changes and What Stays the Same?
Search Engine Optimization, Answer Engine Optimization, Generative Engine Optimization, and Large Language Model Optimization are layered, not competing. SEO gets pages discovered, indexed, and trusted. AEO structures the content on those pages so it can be selected as a direct answer. GEO improves retrievability and grounding inside generative engines. LLMO strengthens entity-level signals so Large Language Models associate your brand with the right concepts.
The shared substrate stays the same: crawlable HTML, clean information architecture, original expertise, and consistent terminology. What changes is the unit of optimization. SEO optimizes the page for a query. AEO optimizes the section for a question. GEO optimizes the passage for retrieval and citation. LLMO optimizes the entity for recognition.
| Layer | Unit | Primary surface | What it adds |
|---|---|---|---|
| SEO | Page | Google, Bing rankings | Discovery, authority, indexation |
| AEO | Section | Featured snippets, AI Overviews, voice | Answer-first structure, schema, snippet readiness |
| GEO | Passage | ChatGPT, Perplexity, Gemini, Copilot | Retrievability, grounding, multimodal readiness |
| LLMO | Entity | Model training, brand mentions | Entity consistency, knowledge-graph alignment |
According to AEO Tester, AEO should be treated as an extension of existing SEO practice rather than a replacement. A long-form SEO page that opens with an answer-first paragraph and uses question-format H2s satisfies both SEO and AEO simultaneously (Source: Unfoldmart) — which is why the archive refresh model works. For a deeper breakdown, see [AEO vs GEO vs LLMO: Which Workflow Fits Your Team?](#).
Which Existing Pages Should You Refresh First for AEO?
Refresh URLs that already have search traction, buyer relevance, and citation potential before touching anything else. The goal is to compound existing authority, not redistribute it. Five archive types tend to convert best: evergreen guides, original frameworks, research reports with proprietary data, glossary and definition pages, and product or category pages where entity clarity matters.
Rank candidate URLs against five practical signals:
- Search traction — the page already ranks page-one or pulls organic clicks for question-shaped queries.
- Buyer relevance — sales, success, or support teams reference it in real conversations.
- Original data or framework — the page contains something only your team could write.
- Citation potential — the topic surfaces in answer-engine prompts your buyers actually ask.
- Topical fit — the page reinforces a hub you want to own, not a stray one-off.
Question mining is the second input. Pull from People Also Ask, sales call transcripts, LinkedIn comments, Reddit threads, support tickets, and live prompt testing in ChatGPT and Perplexity. Hive Strategy recommends identifying 3–5 real questions per topic rather than chasing every long-tail variation — depth beats breadth because Blend B2B notes that one broad article cannot reasonably cover 200 different prompt variations.
| Archive type | Refresh priority | Typical conversion work |
|---|---|---|
| Evergreen guides | High | Add answer blocks, restructure H2s as questions |
| Original frameworks | High | Surface the framework name as an entity, add schema |
| Research reports | High | Pull stats into citable sentences, add attribution |
| Glossary pages | High | Tighten definitions, add entity relationships |
| Product pages | Medium | Add Organization and Product schema, clarify entities |
| Stale campaign pages | Low | Usually merge, redirect, or noindex |
If your team wants the archive triage and conversion handled as a recurring pipeline rather than a one-off project, Mentionwell runs the workflow across one site or hundreds — Get My Site GEO Optimized to start the audit on your existing URLs.
How to Structure Content for AEO When Refreshing an Old Page
Replace the long SEO introduction with a direct answer near the top, then make every H2 or H3 answer one specific question in 40–60 words before expanding. According to Golaco Content, every section should lead with a direct, complete answer in the first 40 to 60 words so AI systems can extract a clean, citable passage; Digital Agency Network lists 40–50 words as a working range. Treat both as guidance, not a hard rule — what matters is that the answer is complete, self-contained, and extractable.
The conversion workflow for a single archived page:
- Identify the implicit question behind each existing H2. Rewrite the heading as that question if it improves clarity.
- Write a 40–60 word direct answer as the first paragraph after each heading. Use subject-verb-object sentences. Name entities by their full proper names.
- Make each section standalone. According to Golaco Content, each section should make complete sense if extracted in isolation, with no pronouns or references that depend on earlier sections.
- Add one citable sentence per section — the sharpest summary of the point, written as a sentence an LLM would lift verbatim.
- Use bullets or numbered steps where they genuinely improve extraction. Bullets work for parallel items; numbered lists work for ordered processes.
- Add a concrete example that stands alone with named tools, numbers, or scenarios.
- Strip filler. Remove "in this section," "as we mentioned earlier," and any sentence that depends on the surrounding narrative.
Before-and-after structure on a typical archived page:
| Element | Old SEO version | AEO refresh |
|---|---|---|
| Intro | 300-word narrative warm-up | 80-word direct answer to the page's main question |
| H2 | "The Importance of Onboarding" | "What Does a Good SaaS Onboarding Flow Include?" |
| First paragraph after H2 | Context and history | 40–60 word direct answer with the named entities |
| Body | Long flowing prose | Standalone subsections with one answer each |
| Examples | Embedded in paragraphs | Pulled out as named, scannable cases |
| Closing | Soft summary | Citable sentence + next action |
Semantic chunking matters more than length. Each logical block should carry a clear topic sentence, the direct claim, and the supporting evidence inside the same chunk (Source: AEO Tester). That is what makes a passage retrievable by Perplexity and quotable by ChatGPT.
How Should Hub-and-Spoke Links and Entities Be Rebuilt Across the Archive?
Retrofit the archive into hub-and-spoke architecture by mapping every URL to a parent concept, then rebuilding internal links so each spoke reinforces its hub. According to Relevant Audience, AI search systems evaluate patterns across a content library, not just a single page, when deciding whether a site genuinely owns a topic. A messy legacy blog with overlapping tags and stale links sends the opposite signal.
Start with a knowledge-graph pass. List the entities your archive should own — products, processes, buyer roles, organizations, platforms, and concepts. For each entity, identify the parent hub page (the broad explainer) and the spoke pages (the specific subtopics). According to SEO Web, an AEO page should be planned around an entity such as a concept, product, process, person, or organization with attributes and relationships, not only around a keyword.
Rebuild internal links with three rules:
- Every spoke links up to its hub using the hub's primary entity name as anchor text.
- Hubs link down to every active spoke, not just the newest ones.
- Sibling spokes cross-link only when the topical relationship is genuine — never as filler.
Reinforce E-E-A-T while you are in the page. Add author attribution with a real bio and credentials, surface original research with attributed numbers, cite reliable sources inline, update the published date when the content changes materially, and standardize terminology so the same entity is not called three different things across the archive (Source: Growth Engines, Vajra Global).
Which Schema Types Help AEO, and When Should You Skip Them?
Use Article or BlogPosting on most editorial pages, FAQPage only when the FAQ content is real and unique, HowTo only for genuine step-by-step processes, Speakable only where voice extraction is appropriate, and Product or Organization where entity clarity matters. JSON-LD is the format Google and Bing prefer; keep it consistent with the visible page content.
| Schema type | Use when | Skip when |
|---|---|---|
| Article / BlogPosting | Most evergreen guides, frameworks, research | — |
| FAQPage | Page contains 3+ real, distinct buyer questions | FAQs were added to chase markup |
| HowTo | Page is a genuine ordered process | Steps are conceptual, not actionable |
| Speakable | Short factual answers suitable for voice | Long-form analysis or opinion |
| Product | Product detail or comparison pages | Editorial pages that mention products |
| Organization | Homepage, about, key brand pages | Article-level pages |
Schema is a clarity layer, not a ranking shortcut — it works when it confirms what the page already says, and fails when it tries to claim something the page does not. Validate every template in Google's Rich Results Test and Schema.org validator before publishing across the archive.
How Do You Prevent Cannibalization When Consolidating Old SEO Pages?
Decide between refresh, merge, redirect, noindex, or leave-as-is using a fixed rule set, then run every consolidation through a migration checklist so SEO signals are preserved. SEO Web notes that a migration checklist is required to avoid cannibalization, but most teams need explicit decision rules first.
Decision rules for overlapping URLs:
- Refresh when the URL has unique authority, traffic, or backlinks and the topic is still relevant. Rewrite for AEO; keep the URL.
- Merge when two URLs cover the same intent and one is clearly stronger. Move the unique content into the winner; 301 the loser.
- Redirect when the page is outdated, low-traffic, and a stronger canonical exists. 301 to the closest topical match.
- Noindex when the page must stay live (campaigns, gated assets) but should not compete in search.
- Leave as-is only when the page is performing, well-structured, and on-topic — rare in legacy archives.
Migration checklist for every consolidated URL:
- Confirm canonical intent and the single winning URL
- Update internal links from the merged or redirected URL
- Remove the old URL from sitemap.xml; add the new one
- Implement a 301 redirect (not 302, not meta refresh)
- Verify crawlability in Google Search Console and Bing Webmaster Tools
- Re-validate structured data on the destination URL
- Check that the destination's H2s, entities, and answer blocks cover the merged content's intent
| Scenario | Action | Risk if ignored |
|---|---|---|
| Two glossary posts on the same term | Merge into the stronger one | Split entity signal across both |
| Stale campaign page with backlinks | 301 to closest evergreen hub | Lost link equity |
| Duplicate product explainers | Merge; redirect the weaker | Ranking volatility |
| Thin long-tail articles | Noindex or merge into hub | Topical authority dilution |
How Should Content, SEO, and Demand Gen Teams Work Together?
Run AEO from a single shared playbook where SEO owns query and archive data, content owns answer quality and editorial structure, demand generation owns buyer questions and conversion context, and operations owns CMS publishing and refresh cadence. According to LinkedIn coverage of cross-functional AEO, content, SEO, and demand gen teams need to work from the same playbook to succeed.
| Function | Owns | Inputs to the playbook |
|---|---|---|
| SEO | Query data, rankings, archive audit | URLs to refresh, schema templates, indexation health |
| Content | Editorial structure, answer quality | Direct-answer blocks, entity consistency, citable sentences |
| Demand gen | Buyer questions, conversion intent | Sales-call questions, ICP prompts, CTA logic |
| Operations | CMS, publishing, refresh cadence | Templates, governance, refresh triggers, QA |
The shared artifacts are the playbook itself: a refresh queue (which URLs, in what order, by which trigger), a question library (the 3–5 real questions per hub topic), an entity glossary (canonical names and aliases), and a measurement dashboard (tracked prompts, cited URLs, refresh outcomes).
Mentionwell sits in the operations layer when teams want the publishing pipeline automated. The workflow is concrete: onboard the domain, define the site profile (audience, tone, entities, competitors blocked), run pipeline stages that build research-grounded drafts with AEO, GEO, LLMO, and SEO structure baked in, publish into the existing CMS or headless stack, and trigger archive refreshes on a recurring cadence. The strategy still belongs to the team; the engine handles the throughput.
How Do You Measure AEO Citations Across AI Answer Engines?
Build a measurement model around tracked prompts, cited domains, cited URLs, and refresh outcomes — not rankings alone. Rankings tell you whether a page is discoverable; citations tell you whether it is being selected. According to Blend B2B, AEO teams should inspect which domains and URLs are being cited across tracked prompts to understand what types of content LLMs surface most often.
The measurement stack:
- Baseline prompt clusters. For each hub topic, define 20–50 prompts that span definitional, comparative, and decision-stage questions. Test them in ChatGPT, Perplexity, Google AI Overviews, Gemini, Claude, and Microsoft Copilot.
- Track citation events. Record when your domain is cited, which URL is cited, the surrounding answer text, and which competitors are cited alongside you.
- Analyze citation patterns. Group by prompt cluster, engine, and URL. Identify which page types and structures earn the most citations.
- Tie refreshes to outcomes. When a URL is refreshed, re-run the prompt cluster after 2–4 weeks. Compare citation rate, position in the answer, and competitor displacement.
- Layer classic SEO signals. Continue tracking rankings, impressions, and clicks in Google Search Console and Bing Webmaster Tools as the discoverability floor.
| Signal | What it tells you | Where to measure |
|---|---|---|
| Cited URL | Which exact page is selected | Manual prompt testing, GEO tracking tools |
| Cited domain | Whether your brand is being recognized at all | Prompt logs across engines |
| Answer inclusion | Whether your content is quoted, paraphrased, or just listed | Compare answer text to source |
| Competitor co-citation | Who shows up alongside you | Tracked prompts |
| Refresh outcome | Whether the rewrite moved citation rate | Pre/post prompt re-runs |
How Can Teams Scale AEO Programmatically Without Thin Template Content?
Scale AEO with operating controls — reusable templates, mandatory entity fields, question sets, source requirements, and editorial QA — not bulk output. Programmatic AEO works when consistency is enforced across pages; it fails when templates produce filler.
Controls that prevent thin content at scale:
- Reusable page templates with required slots: page question, 40–60 word answer, entity glossary, hub link, internal links to 3+ spokes, citable sentence, schema block.
- Mandatory entity fields on every page so the same product, process, or concept is named consistently across the archive.
- Question sets of 3–5 real buyer questions per topic, sourced from sales calls, support tickets, and prompt testing — not auto-generated from keyword tools.
- Source requirements that block publication unless every factual claim has an attributed source.
- Editorial QA with a human reviewer checking answer-first structure, entity consistency, and standalone section logic.
- Schema validation against Rich Results Test before any URL goes live.
- Refresh triggers based on citation drift, ranking decay, or material content changes — not arbitrary calendars.
| Control | Without it | With it |
|---|---|---|
| Page template | Inconsistent structure across pages | Predictable extraction surface |
| Entity field | Same concept named three ways | One canonical entity per page |
| Question set | Generated long-tail filler | Real buyer questions only |
| Source requirement | Unattributed claims | Every fact traceable |
| Schema validation | Markup debt | Clean rich-results eligibility |
For deeper terminology coverage as your program scales, the Mentionwell glossary covers [AEO](#), [GEO](#), [LLMO](#), [AI Overviews](#), [ChatGPT](#), [Perplexity](#), and [llms.txt](#).
If your team wants the publishing engine handled — onboarding, site profile, pipeline stages, CMS delivery, and recurring archive refreshes — Mentionwell runs the workflow across one site or hundreds, with AEO, GEO, LLMO, and SEO built into every draft. Get My Site GEO Optimized to start the conversion on your existing archive.
Sources
- SEO vs. AEO: The Content Optimization Shift You Can't Ignoremavencollectivemarketing.com
- How Should Content, SEO and Demand Gen Teams Work Together ...www.linkedin.com
- Evolving From SEO to AEO: How SMART Agencies Are Rethinking ...blog.hivestrategy.com
- AEO: Optimizing Existing Content for AI Searchwww.relevantaudience.com