What Does Peec AI Track, and Why Does the Score Matter?
Peec AI is an AI-search visibility analytics platform that tracks how often a brand appears in answers from ChatGPT, Perplexity, and Gemini, with adjacent claims around Google AI Overviews depending on the source. It is not the PEEC curriculum from the Institute of Positive Education, the PECS Polar Expeditions Classification Scheme, RunPee's PeeTimes, Peecoin, Play-Cricket's PCS scoring, or the PE professional engineering exam — all of which surface for the same query string and confuse the SERP.
The score Peec produces is a diagnostic instrument. It tells a marketing team how visible their brand is across answer engines, which competitors are gaining position, and which sources those engines lean on. According to Peec AI's own product copy, the platform is built to "analyze brand performance across ChatGPT, Perplexity, and Gemini." That framing matters: Peec measures what the engines are already doing.
The score is the readout, not the lever. Peec can show that a brand appears in 12% of ChatGPT answers for a tracked prompt set this week and 18% next week, but the movement comes from changes in the underlying corpus — new pages, refreshed pages, third-party mentions, model updates, and indexing cycles. A dashboard does not write a comparison page, refresh a glossary, or close a citation gap on a competitor's G2 review. The team using the dashboard does.
This is the central distinction worth holding through the rest of this article: measurement is one layer, content operations is another, and the score only changes when something actionable happens between them.
Which Platforms Does Peec AI Cover: ChatGPT, Perplexity, Gemini, Google AI Overviews, Claude, or AI Mode?
Peec AI's own copy names ChatGPT, Perplexity, and Gemini as the tracked surfaces. Third-party sources describe coverage differently, and the conflict matters before purchase. Verify current platform coverage directly with Peec AI before buying — the most specific limitations in the corpus come from competitor pages, not from Peec or from independent reviews.
Here is the coverage as different sources describe it:
| Source | Platforms named | Notes |
|---|---|---|
| Peec AI (own copy) | ChatGPT, Perplexity, Gemini | Product changelog and homepage framing |
| Geneo (review) | ChatGPT, Perplexity, Google AI Overviews | Substitutes AI Overviews for Gemini |
| LLM Pulse (competitor) | ChatGPT, Perplexity, plus paid add-ons for Gemini, AI Mode, Claude | Conflicts with Peec naming Gemini in base coverage |
| Trakkr (competitor) | 3 platforms (unspecified) vs Trakkr's 8: ChatGPT, Claude, Perplexity, Gemini, Copilot, Meta AI, AI Overviews, Grok | Used as a competitive contrast |
Two surfaces a buyer should ask about explicitly: Google AI Overviews (sometimes conflated with Gemini, sometimes broken out separately) and Google AI Mode, which is a distinct surface. Claude, Microsoft Copilot, Meta AI, and Grok are the next tier of questions — none of them are mentioned in Peec AI's own naming, but at least one competitor source treats Claude and AI Mode as paid add-ons rather than excluded entirely.
What Does the Peec "Score" Actually Represent?
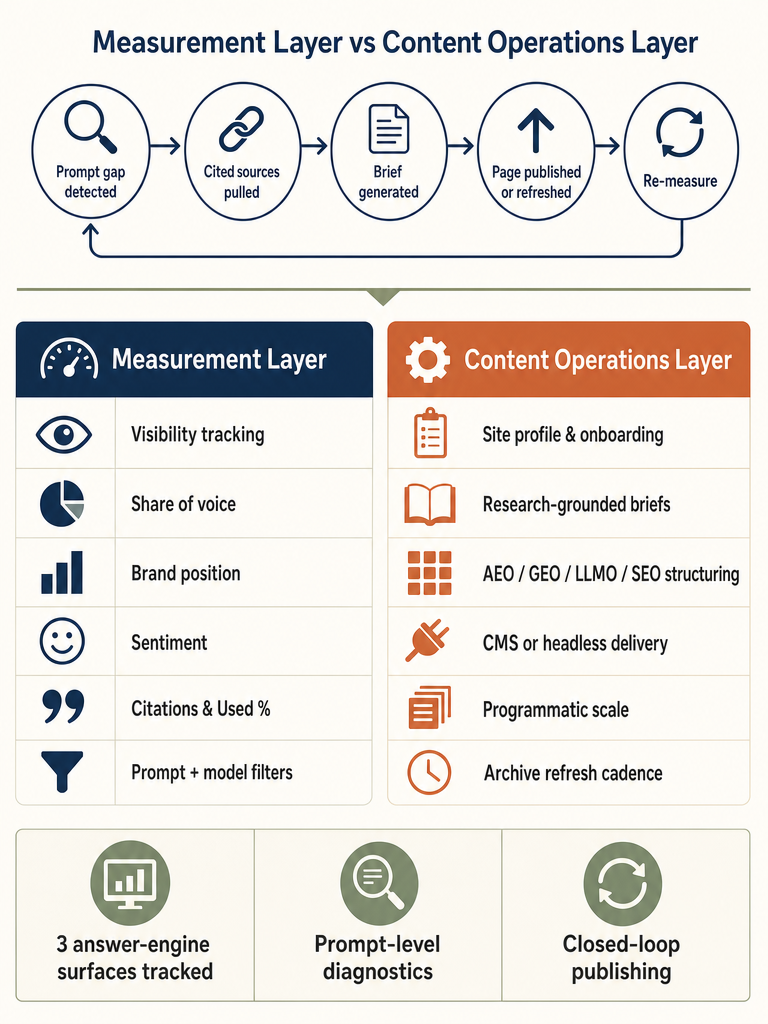
The Peec score is a composite of visibility, share of voice, brand position, sentiment, and citation metrics across a selectable reporting window — a readout of how answer engines are treating a brand across a tracked prompt set, not a single proprietary number with a published formula. According to Geneo's 2025 review, the dashboard "ranks tracked brands by visibility, position, and sentiment, and highlights changes over a selectable window," and exposes per-source metrics including Used % and Avg. citations with prompt-level and model-level filters.
The components surfaced across the corpus:
- Visibility: how often the brand appears in answers to tracked prompts
- Share of voice: the brand's appearance rate relative to a competitor set
- Brand position: where the brand sits in a ranked or listed answer
- Sentiment: tone of the mention when the brand is included
- Citations: which URLs the model cited when generating the answer
- Used %: how frequently a given source domain is cited across the prompt set
- Avg. citations: average citation density per answer
- Filters: prompt-level and model-level slicing across selectable date ranges
None of the supplied sources publish the formula or weightings behind the composite score. That is a meaningful gap. A rising Peec score is a signal to investigate, not a conclusion. When the number moves, the operator's job is to inspect which prompts changed, which competitors gained or lost ground, and which cited sources influenced the shift — editorial, user-generated, corporate, reference, or institutional. The score points at the door; the source breakdown tells you which door.
Peec AI shows the score. Mentionwell ships the citation-ready content that moves it. Get My Site GEO Optimized to turn prompt-level findings into published pages.
What Sources Does AI Cite When Competitors Outrank You in AI Search?
When a competitor outranks your brand in an AI answer, the cited sources tell you what to build. According to Geneo's review of Peec AI, the platform categorizes cited domains into five buckets: editorial, user-generated content (Reddit, G2, YouTube), corporate, reference, and institutional. Each bucket implies a different content move.
The diagnostic workflow:
- Identify a prompt where a competitor wins and your brand is missing or trailing.
- Pull the cited sources for that prompt.
- Classify each cited domain by category.
- Read the source mix as a strategy signal.
The source mix dictates the response:
| Cited source category | What it means | What to build |
|---|---|---|
| Editorial (TechCrunch, industry press) | The model trusts third-party reporting | Pursue earned coverage; an owned page alone may not close the gap |
| User-generated (Reddit, G2, YouTube) | Community signal carries weight for this prompt | Invest in review presence, community participation, and video |
| Corporate (competitor's own pages) | A comparison, glossary, integration, or use-case page is doing the work | Build or refresh the equivalent owned page |
| Reference (Wikipedia, glossaries) | The model is grounding on definitional content | Build entity pages, glossary entries, schema-rich definitions |
| Institutional (.gov, .edu, standards bodies) | The model is anchoring on authority sources | Cite and link to those sources in your own coverage |
When AI systems cite a competitor's corporate pages — their pricing page, their integration page, their "X vs Y" comparison — that is the most actionable signal in the dashboard. Refreshing or building the equivalent owned page is usually the highest-leverage move available, because it is the only category fully under the team's control. When the cited sources are user-generated or editorial, owned content is part of a longer play, not a same-week fix.
What Is MCP, and What Does Peec MCP Add Beyond the Dashboard?
Model Context Protocol, or MCP, is an open specification that lets AI tools query external data sources, reason over the results, and trigger actions in connected systems. Peec MCP is Peec AI's implementation of that protocol — a live data layer that exposes Peec's visibility, citation, and competitor data to any MCP-capable AI client.
According to Peec AI's own documentation, Peec MCP enables AI tools to:
- Pull current visibility and citation data for a tracked brand
- Identify prompts where competitors outrank the brand
- Return the cited sources for those prompts
- Generate a content brief with topic, angle, structure, and source list
- Send Slack summaries (including per-client Monday digests for agencies)
- Draft reports, fill spreadsheets, and trigger publishing actions through tools such as n8n or Make
This is where measurement starts to lean toward action. A natural-language query to an MCP-connected client — "show me the five prompts where we lost ground this week and draft briefs for them" — collapses what was previously several dashboard sessions into one workflow.
The supplied sources describe what MCP can do, but they do not cover the governance model. For agencies and multi-site operators, that gap is the entire question. A brief generated from a Peec prompt analysis is a starting point — not a finished page, and certainly not one ready for the CMS without human review.
How Do Peec Insights Become an Editorial Brief, Article, Page Update, or Archive Refresh?
The closed-loop workflow is the part the SERP does not cover. Measuring is one act; turning measurement into published, citation-shaped content across one site or hundreds is another. Here is the operational path from a Peec AI finding to a re-measured prompt.
- Identify prompt gaps. Filter the dashboard for prompts where the brand is absent, trailing, or losing share of voice over the selected window. Prioritize prompts with commercial intent and recurring competitor wins.
- Pull cited sources. For each priority prompt, export the cited URLs and their domains. Note frequency (Used %) and citation density (Avg. citations) per source.
- Classify source types. Tag each cited source as editorial, user-generated, corporate, reference, or institutional. The mix decides the play.
- Decide create or refresh. If an existing owned page targets the prompt but is not getting cited, the move is usually a refresh — updated entities, sharper direct answers, current statistics, schema. If no owned page exists, scope a new one.
- Build a research-backed brief. Pull the actual cited sources into the brief. Identify the entities, statistics, and direct-answer phrasings the model is rewarding. Note the competitors winning the prompt and how their pages are structured.
- Structure for AEO, GEO, LLMO, and SEO together. A direct-answer opening for AEO. Entity density and citable phrasings for GEO. Source attribution and structured data for LLMO. Internal linking, indexing, and topical depth for classic SEO. These are not four separate workflows — they are four lenses on the same page.
- Publish through the CMS or headless stack. Brand voice, internal links, schema, and refresh metadata applied consistently. For multi-site operators, that consistency is what makes the workflow scale.
- Re-measure prompts after indexing and model refresh cycles. Indexing lag and model retraining mean the score will not move the day after publish. Set a 4-, 8-, and 12-week re-measurement cadence per prompt cohort.
This is where Mentionwell fits. Peec AI answers "where are we losing?" Mentionwell answers "what do we ship, and how do we ship it consistently across the archive?" The Mentionwell pipeline takes a Peec-style finding — a prompt gap, a source mix, a competitor's cited page — and runs it through onboarding, site profile, research-backed brief, citation-shaped draft, brand-controlled review, CMS or headless delivery, and scheduled refresh. Measurement without a publishing engine produces dashboards. Measurement plus a publishing engine produces citations.
Peec AI vs Mentionwell: Measurement Layer vs Content Operations Layer
Peec AI is the measurement layer; Mentionwell is the content operations layer. They sit at different points in the AI-search stack and solve different problems — treating them as alternatives is a category error, treating them as complementary is the operating model.
| Capability | Peec AI | Mentionwell |
|---|---|---|
| Visibility tracking across ChatGPT, Perplexity, Gemini | Yes | No |
| Competitor benchmarking and share of voice | Yes | No |
| Cited-source diagnostics by category | Yes | No |
| MCP data layer for AI clients | Yes | No |
| Research-backed editorial briefs | Brief generation via MCP | Core workflow |
| Citation-shaped article production (AEO, GEO, LLMO, SEO) | No | Core workflow |
| CMS and headless publishing | No | Core workflow |
| Multi-site and agency content operations | Limited (per-client summaries) | Core workflow |
| Programmatic SEO and glossary-style coverage | No | Core workflow |
| Archive refreshes on a governed cadence | No | Core workflow |
Peec AI helps a team see the score. Mentionwell helps a team change it by building and maintaining the corpus that answer engines can actually cite. The measurement layer identifies the gap; the content operations layer closes it. A team running Peec AI without a publishing engine has high-resolution dashboards and a slow content pipeline. A team running Mentionwell without measurement is shipping into the dark. The combination is what compounds.
For agencies and multi-site operators, the asymmetry is sharper. A measurement tool reports on each client's visibility separately. A content engine has to ship brand-consistent, citation-shaped output across every domain on a repeatable cadence. Those are different operational problems.
Is Peec AI Worth the Investment If You Still Need to Ship Content?
Peec AI is worth the investment for teams with the publishing capacity to act on its findings — without that capacity, the dashboard becomes a backlog generator. The analytics value is well-supported in the corpus; specific pricing claims are not.
According to LLM Pulse, Peec AI starts at €85/month for 50 prompts across 3 models — or €1.70 per prompt — and LLM Pulse positions its own Starter tier at €49/month for 50 prompts across 5 AI models, claiming a 42% lower cost per prompt. Trakkr separately positions itself at $49/month and describes that as roughly half of Peec AI's cost. Both numbers come from competitor pages and should be verified against Peec AI's current pricing before any procurement decision.
A practical buyer checklist:
- Platform coverage: confirm in writing which surfaces are included in the base tier and which are paid add-ons. Specifically ask about Gemini, Google AI Overviews, AI Mode, Claude, Copilot, Meta AI, and Grok.
- Prompt volume: estimate prompts needed per tracked brand, per competitor cohort, per market. The €1.70-per-prompt math compounds quickly across multi-site portfolios.
- Source-level diagnostics: confirm Used %, Avg. citations, prompt filters, and model filters are available at the tier you're considering.
- MCP and governance: if you plan to connect MCP to publishing tools, define editorial review gates and CMS permissions before signing.
- Export and reporting: confirm raw data export, scheduled reports, and integration paths (Slack, n8n, Make, spreadsheets).
- CMS workflow: separate question — what publishing engine ships the briefs Peec AI generates?
- Refresh cadence: who owns the archive refresh schedule once gaps are identified?
- Team capacity: a measurement tool without a publishing engine produces backlog, not citations.
The right pairing is measurement plus content operations — Peec AI to identify where the score is weak, Mentionwell to ship the citation-ready pages, refreshes, and programmatic coverage that move it. To turn Peec-style findings into a governed publishing pipeline across one site or hundreds, Get My Site GEO Optimized with Mentionwell.
Sources
- Peec AI Review: is it worth it in 2026? - Airefsgetairefs.com
- Understanding the PE Exam Scoring System - YouTubewww.youtube.com
- Learn About PEECteachpeec.com
- Peec AI Review 2026: Is It Worth the Investment? | Rankability Blogwww.rankability.com
- PEEC FAQs - Institute of Positive Educationshop.instituteofpositiveeducation.com
- Peec AI MCP - Peec AIpeec.ai